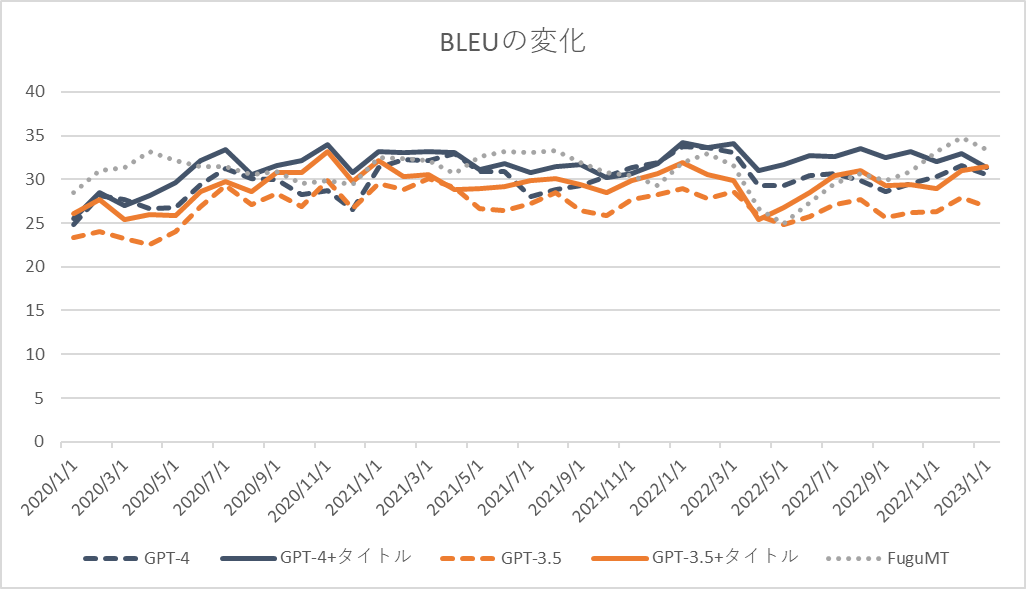
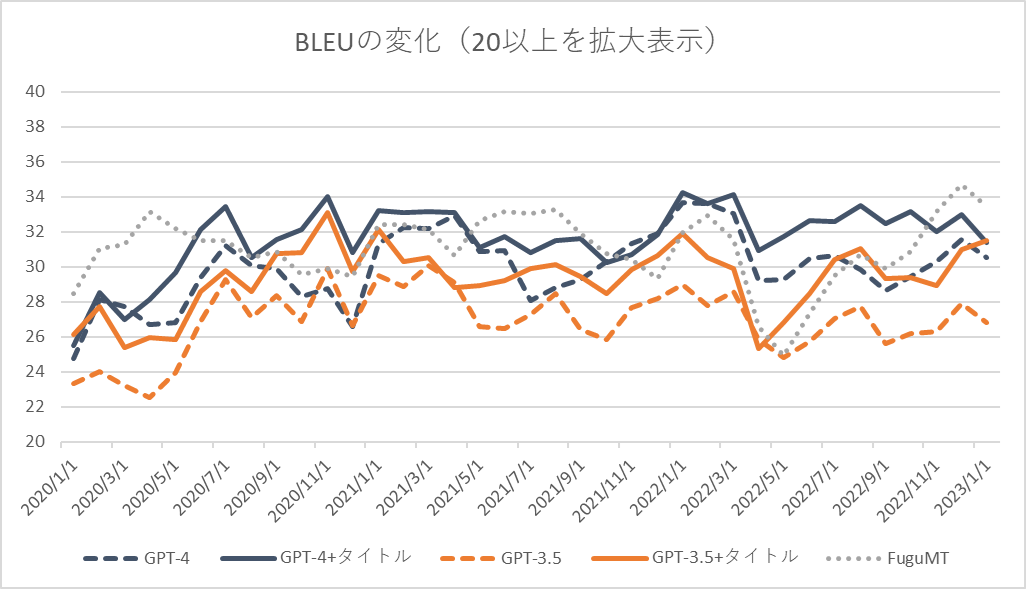
MPT-30Bの性能が高いと聞いてそのChat版であるmosaicml/mpt-30b-chat · Hugging Faceの性能を検証してみた。過去の事例通り機械翻訳(英文和訳)でGPT-3.5、GPT-4と性能を比較した。結果、パラメータ数の割に高い性能を持っていることが分かった[1]。
MPT-30B-ChatのライセンスはCC-By-NC-SA-4.0 (non-commercial use only)であることに注意が必要である。Apache-2.0のMPT-30BやCC-By-SA-3.0のMPT-30B-Instructとはライセンスが異なる。
| モデル / shot数 / 備考 | BLEU |
| MPT-30B-Chat / 0 shot / モデル出力のまま | 7.7 |
| MPT-30B-Chat / 0 shot / ルールで回答抽出 | 13.0 |
| MPT-30B-Chat / 0 shot / 手で回答抽出 | 13.8 |
| MPT-30B-Chat / 3 shot / モデル出力のまま | 16.1 |
| MPT-30B-Chat / 3 shot / ルールで回答抽出 | 29.2 |
| MPT-30B-Chat / 3 shot / 手で回答抽出 | 30.9 |
| gpt-3.5-turbo-16k-0613 / 3 shot | 35.3 |
| gpt-4-0613 / 3 shot | 32.1 |
| gpt-4-0314 / 3 shot | 36.5 |
性能評価の方法
性能評価に使用したデータは以前(GPT-4を用いた翻訳の検証(vs GPT-3.5 vs FuguMT) | ぷるーふおぶこんせぷと (staka.jp))と同様であるが、処理時間の関係上[2]、50件をサンプリングした。
- 英語文を日本語文に翻訳し、その性能を評価した。評価指標はBLEUで、使用したツールやtokenizerは前回と同じ(sacrebleu –tokenize ja-mecab)である。
- データセットは外務省WEBサイトのプレスリリース(CC BY互換で利用可)のうち日本語、英語が対応しているページを利用した。評価に使用した対訳ペアは前回と同じ。2020年1月~2023年3月で月ごとに5件のプレスリリースを選択し全195件を取得、その上でさらに50件サンプリングした[3]。
- OpenICLを用いて事例部分を取得した。RetrieverにはTopkRetriever[2101.06804] What Makes Good In-Context Examples for GPT-$3$? (arxiv.org)」を用いた。3 shotと書かれた行については全く同じデータを使っている。
- 入力データは前回GPT-3.5/4の比較で使用したものと可能な限り合わせて作成した。プロンプトの作成はMPT-30B-Chat – a Hugging Face Space by mosaicmlを参考にしている[4]。
- 処理時間削減のためMPT-30B-Chatは「load_in_8bit=True」で読み込んでいる。
- MPT-30B-Chatの出力は回答部分の特定が一筋縄ではいかないことがある。複数の方法で回答部分の特定を行った。[4][5]
- モデル出力のまま:出力をそのまま利用
- ルールで回答抽出:正規表現を用い<|im_start|>や<|im_end|>をいくつかのパターンで指定して回答部分を取得
- 手で回答抽出:目で見て回答部分を特定
結果とまとめ
MPT-30B-Chatは長いコンテキストに対応していることからIn-Context Learningが有効に機能する。出力から回答部分を特定することは簡単ではないが、うまくルール化することでGPT-3.5に近い性能を出すことができる。これらの処理はライブラリが対応すればよく、単純なルールでも比較的良いスコアが出せる[4]。
スコア上はMPT-30B-Chat+3 shotのICLでzero shotのGPT-3.5以上の性能が出せている。日本語に対応していてローカル環境で動くLLMとしては非常に優秀である[6]。オープンなライセンスのLLMであることから日本語能力の強化も有望そうで今後が非常に楽しみ。
脚注
[1] (最近色々言われている)GPT-3.5やGPT-4のサイズと比べるとかなり小規模。
[2] 「その他」にも書いている通り、検証するのも結構な計算リソースが必要。ICLを使ってコンテキストが長いのでしょうがない面はあるが…(3 shotではなくzero shotだとかなり速い)
[3] 一定期間ごとにサンプリングしている。
[4] 簡単に使えるライブラリが欲しい。誰か作っていそうではあるし既存の何かのライブラリでサポートされそうな気もする。
[5] ルールを追加するなどして自動化したかったが時間の関係上断念した。これらの処理は回答の特定を目的としており回答中のおかしな出力を除去したりはしていない。「手で回答抽出」は頑張ってルール化したときの最善の結果として記載している。
[6] これは本当にそう思う。
[7] 中国語など他の言語が混ざることがある、日本語としておかしな表現が出力されることがある、など印象の悪い出力が混ざることがある。これらが悪い方向に目立つのは事実。
その他
MPT-30B-Chatを検証したところGPT-4や3.5にかなり迫っている感じがあり驚いた。とはいえ、目検証をしてみるとBLEU以上の差は感じなくもなく日本語能力は十分とは言い難い[7]。機械翻訳能力だけでなく総合的なベンチマークもしてみたいところ。
検証はCloab Pro+のA100 GPU、load_in_8bit=Trueで実施した。この環境でもコンテキストが長い(7000文字)場合は5-10分の処理時間が必要だった。公式の説明通りbfloat16+triton構成では20-30分かかる。高速化手法は色々あるとはいえ実利用で安定動作させるのはかなり大変そうではある。