Fugu-MT: arxivの論文翻訳(概要)をMCP(Model Context Protocol [1] )に対応させた。実装にはGradio(Building Mcp Server With Gradio)を使っている。Claude desktopからも接続ができ便利である。
Gradio[mcp]
fugumt.comのMCP対応にはgradio[mcp] [2] を用いた。gradioでは 「(1) included a detailed docstring for our function, and (2) set mcp_server=True in .launch()
」 とするだけでMCP serverを実装できる。具体的なコードは
def search_papers(keywords: str, start: str, end: str):
"""arXivのAI関連論文を検索しMarkdownで返します。AI関連論文のみのデータベースなので検索キーワードは5個以下にすることをお勧めします。現状はベクトル検索に対応していません。
Args:
keywords: 検索用の単語リスト。" "スペース区切りを想定。全てが必須のキーワードで3 - 5 wordsが推奨値。
start: 検索の開始日。yyyy-mm-dd表記を想定。この日付以降の論文を検索。
end: 検索の終了日。yyyy-mm-dd表記を想定。この日付以前の論文を検索。
"""である。上記に対応してmcpsearch.fugumt.com/gradio_api/mcp/schemaのようにschemaが作られる。使用方法などはhttps://mcpsearch.fugumt.com/?view=apiから確認できる [3] 。
Claude desktopでの利用例
Claude desktopでfugumtのMCP serverを利用するにはFor Claude Desktop Users – Model Context Protocolのようにセットアップし、「claude_desktop_config.json」に下記設定を行えばよい。
{
"mcpServers": {
"fugumt": {
"command": "npx",
"args": [
"mcp-remote",
"https://mcpsearch.fugumt.com/gradio_api/mcp/sse"
]
}
}
}Building Mcp Server With Gradioの3.に書かれているように「Some MCP Clients, notably Claude Desktop, do not yet support SSE-based MCP Servers. In those cases, you can use a tool such as mcp-remote. First install Node.js. 」であるため、Claude desktop利用時はNode.jsのインストールも必要である [4]。
実行例は下記の通り。
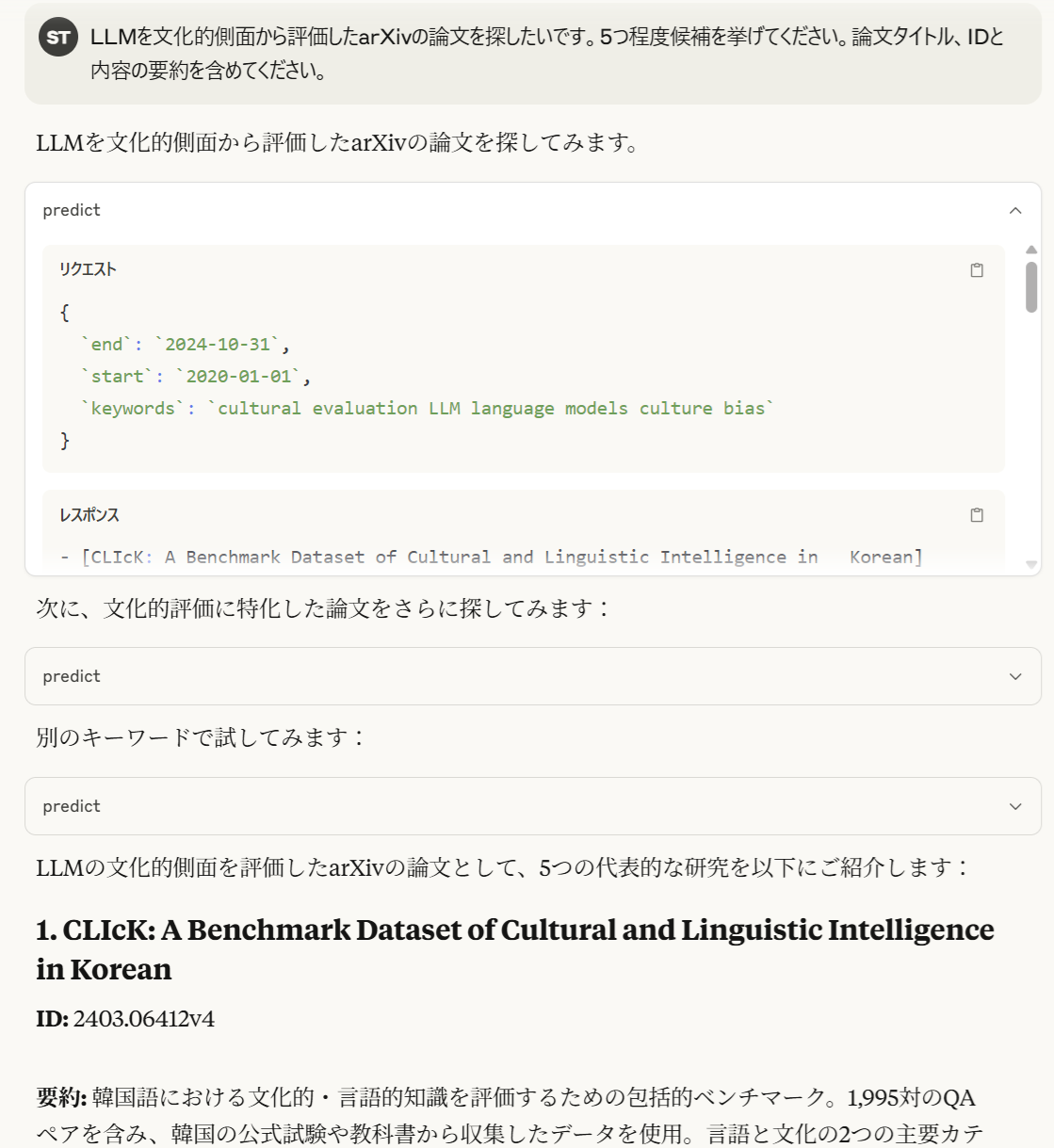
fugumt.comのMCPサーバを利用した応答ができている(https://claude.ai/share/f19d4dda-e264-4486-a3ad-0af1d723ed76)。
gradioを使うと非常に簡単にMCP serverを実装できる。arXivのAI関連論文を検索を含めてarXiv論文を探す場合にぜひ利用してほしい [5]。
脚注
[1] AIアシスタント(LLMアプリケーション)がデータソースやツールと連携するためのプロトコル(Introducing the Model Context Protocol \ Anthropic)
[2] Building Mcp Server With Gradioの通り。
[3] 使用方法などドキュメントを含めて自動生成されるのはとても便利。
[4] クライアントによっては「”url”: “https://mcpsearch.fugumt.com/gradio_api/mcp/sse”」の記載でOKのよう。
[5] と言いつつ安定稼働はしていないと思われる… vector searchへの対応や関連論文リスト取得をサポートするなど拡張もしていきたいと思っている。


