論文確認時にAIを使うことが多くなっていることもあり、arXiv最新論文の紹介の完全自動化を行った。今後は「FuguReport」に引っ越す(?)[1]予定である。
FuguReportの概要と実装方針
Fugu ReportにはDaily ReportとWeekly Reportの2つがある。Daily Reportは注目すべき個別論文の紹介、Weekly Reportは週次で注目すべきテーマの紹介を行う構成にしている。大体のイメージは下表のとおりである。
| Daily Report | Weekly Report |
| ① 毎日自動作成 ② 日次で注目すべき最大5論文を選びそれぞれを要約する ③ 論文の抽出はfugumtのスコアの他、他サイトの注目度を加味する[2] | ① 週次で日曜日に自動作成 ② 過去1週間に盛り上がった3テーマについてレポートを作成する ③ テーマの選別はfugumtのスコアの他、論文間の距離を利用して遠いテーマを選別する |
両レポートともfugumtのスコアを活用している事、ライセンス関係に気を付けている事[3]、日本語と英語版の2つを作成する事は共通である。今のところ基本部分の生成にはGPT-5.4、レビュー修正にはClaude Opus 4.6を用いている[4]。なお、ツールとして独立できる部分はMCP Serverとして分離する構成にしている。次々とツール使っているAI Agentと呼んで良いアーキテクチャになっている。
Daily Reportの生成手法
Daily Reportは下記の方針で生成。オーソドックスなフローとなっている。
- 対象論文の選定
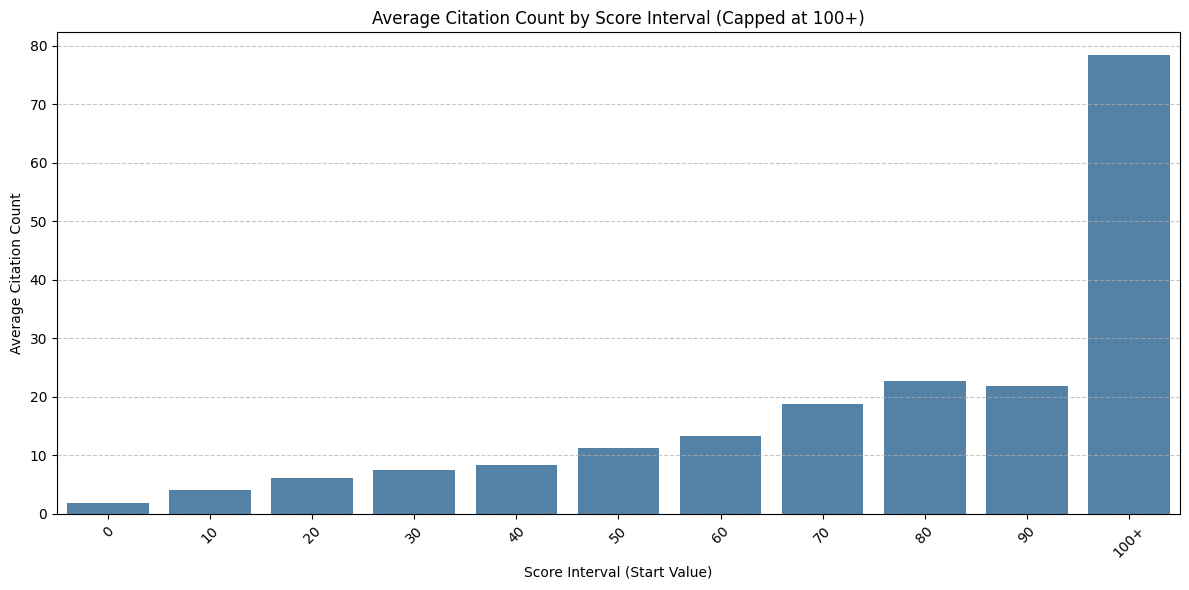
- Creative Commonsライセンスか否か(および本文取得が可能か)、fugumt score、引用件数、SNSやWEBサイトでの言及数[5]などから注目すべき論文を選定
- メタデータと論文情報の取得
- 著者所属、キーワード及びその階層構造、プロジェクトサイトやgithubリポジトリなど重要情報の取得
- Draft(GPT-5.4)→ Review(Claude Opus 4.6)→ Translate(GPT-5.4)の 3 段階で処理
Weekly Reportの生成手法
WeeklyレポートはDaily Reportより凝った構成としている。
- 週次で盛り上がったテーマを選定
- fugumt scoreをベースに対象週の候補論文群を選定
- 候補論文群のそれぞれの論文のベクトルを求めそれぞれの距離を計算
- Abstract、論文カテゴリ、キーワードの 3 種 embedding を取得しコサイン距離を計算[6]。
- 3 テーマ選定、最高スコア論文を 1 テーマ目として採用し、2 本目以降は「選択されたテーマから遠くかつスコアが高い」論文を選択
※ テーマの多様性を確保
- 各テーマの代表論文の選定
- 各テーマに関連する論文でCC ZERO、CC BY、CC BY-SAと本文が扱えるものを選定
- 最大 10 本を比較プールに蓄積し、fugumt score、論文の意味的距離、LLM as a Judgeによる比較選定を組み合わせ、最大 3 本を決定
- Introduction / Future Work の抽出
- 代表論文の本文のうち、IntroductionとFuture Workに関する部分を抽出
※ 全く抽出できない場合は次順位の論文を試す
- 代表論文の本文のうち、IntroductionとFuture Workに関する部分を抽出
- 段階的なレポート生成
- テーマ現状の生成、代表論文 3 本の Introduction を中心として「主要課題」「研究の方向性」「代表論文の役割分担」を 記述
- 週内進展の生成、テーマに属する週内論文(上位 10 件)についてテーマのどの点を前進させたかを記載
- 展望の生成、代表論文 3 本の Future Work と週内進展を入力として「近い将来に増えそうな方向性」「技術的ボトルネック」「次の論点」を記述
- 別モデルによるレビューと全文リライト
- 初稿生成とは別モデルで査読、最終版を確定
- 日本語翻訳
- インフォグラフィクス生成
週次で盛り上がったテーマ選定に力を入れたフローとなっている。この選定はLLM as a judgeでは困難であり、fugumt scoreやWEB/SNSでの反応といったProxy的な指標が重要となる。段階的な生成と別モデルによるレビューも品質向上には効果があった[7]。
所感
生成AIの品質が向上していることもありレポートのクオリティはかなり高い。しばらくはチェックしながらの運用になると思うがdevneko.jpは3月末で更新を停止する予定である。
いろいろと試していて思ったがDaily Report、Weekly Reportとも難しいのは要約そのものよりも評価に関わる部分、という印象だった。[8]。
※ここ最近のfugumt score推しは上記が原因
対象テーマ選定や対象論文選定ができれば、それ以降の処理は自動化が容易で生成品質も高い。別モデルでのレビューは効果があるので入れているもののレビュー・修正は1回で十分な印象。すごい時代になったなーと思う。
脚注
[1] もはや人が関わっていないので紹介Blogではなく整理システムになっている。
[2] 本文を扱うことが多いので基本的にCreative Commonsライセンスの論文を選択する。
[3] 本文を扱う場合はCC ZERO、CC BY、CC BY-SAの論文を使用する。v1とv2のライセンスが異なる場合もあるので取得可能な全バージョンについて確認している。
[4] 著者所属、カテゴリ、論文分類など基礎情報の整理にはGPT-4.1、GPT-4.1 nano、Mistral Small、DeepSeek V3.2を用いているなど複数のLLM/LRMを使い分けている。
[5] 一部は十分に効いていないので今後強化を行う予定。
[6] Abstractのみよりも効果があった。
[7] 英語での処理を優先しているのはコストパフォーマンスを上げるためである(元データが英語なのでできるだけ英語で扱った方が品質面で有利でありトークンも節約できる)
[8] 実際のところ人間にも難しい。(が、これは凄い!と思う直観が働くことは少なからずある。AIの能力向上でこのあたりも解決するかもしれない。)
{kind=link}
{kind=link}