[1] 正直、大幅な性能向上という効果は見られなかった。1 shotではほぼ効果が無く、zero shotでは日本語で指示を与えた方が良いようにも見えたがそもそものBLEUが低いため参考にはならない印象。なお、Weblab-10Bについてはfew shot部分を公式の「\n\n### 指示:\n{} \n\n### 応答:\n{}」に合わせるのは効果がありそうだった。 [2] stabilityai/stablelm-base-alpha-7b · Hugging Face [3] stabilityai/japanese-stablelm-instruct-alpha-7b · Hugging Face [4] rinna/bilingual-gpt-neox-4b-instruction-sft · Hugging Face [5] 以前と同じでOpenICL、TopkRetrieverにより取得 [6] gpt-3.5-turbo-16k-0613 [7] Qwen/Qwen-7B-Chat · Hugging Face [8] matsuo-lab/weblab-10b-instruction-sft · Hugging Face [9] 回答を手動抽出した場合の性能はLlama-2-7b-chat-hf: 23.9、Llama-2-13b-chat-hf: 35.1、PolyLM-13B: 25.8 [10] Qwenは商用利用可能そうだが「If you are commercially using the Materials, and your product or service has more than 100 million monthly active users」や「You can not use the Materials or any output therefrom to improve any other large language model (excluding Tongyi Qianwen or derivative works thereof).」との記載がある。また、HuggingFaceのページには「If you have requirements for commercial use, please fill out the form to apply.」というフォームが用意されている。Weblab-10BはCC BY-NCなので商用利用不可。 [11] モデルが公開されていれば検証はできるが正しく検証できているかは謎な部分がある。特に「それぞれのモデルで最適なプロンプト」「Few shot事例の与え方」は使ったデータにも依存するわけで開発元の公式な情報があると良いなとは思う。
[1] GPUで動作させる部分だけ若干コードを追加している。cerebras/Cerebras-GPT-13B · Hugging Faceは書かれた手順ではメモリ不足になる。float16にすれば動作する。 [2] この後改行して「私は、それぞれの言葉についちゃった。「お父さん、こんなに美しい犬がいますか?」「この人、あなたのほうが素敵ですよ」」・・・と謎の文字列が続く。 [3] Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. 2020. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv preprint arXiv:2101.00027. [4]とても雑なことは承知しつつ、日本語判定は結構難しく判定に凝ると処理時間の問題が出るため今回はこの条件で検証した。日本語分を多めにカウントしていて出た結果で結論には影響しない。 [5] 「的」が入っているのは中国語も入っているからかな?と思う。
その他
The Pileを使って構築した大規模言語モデルで何故か日本語が使えるのは知られていた。その理由としてGithubデータセットの日本語コメントによるものなどの理由を聞いたこともあったが、本当か確証がなかったので調べてみた。結果当たらずも遠からずという感じだった(構成要素としてはそれなりに多いが半分は超えていない)。
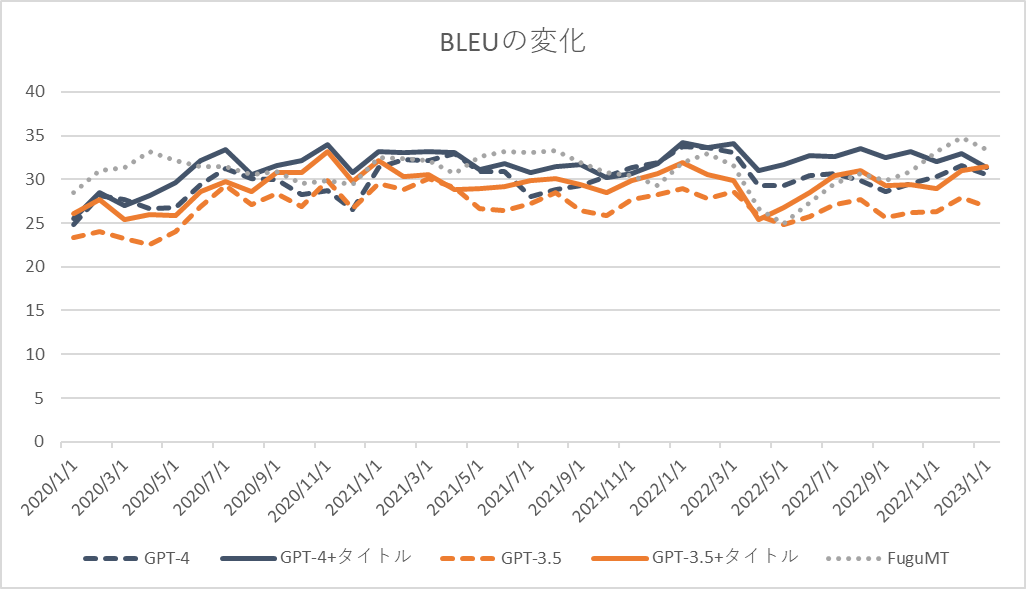
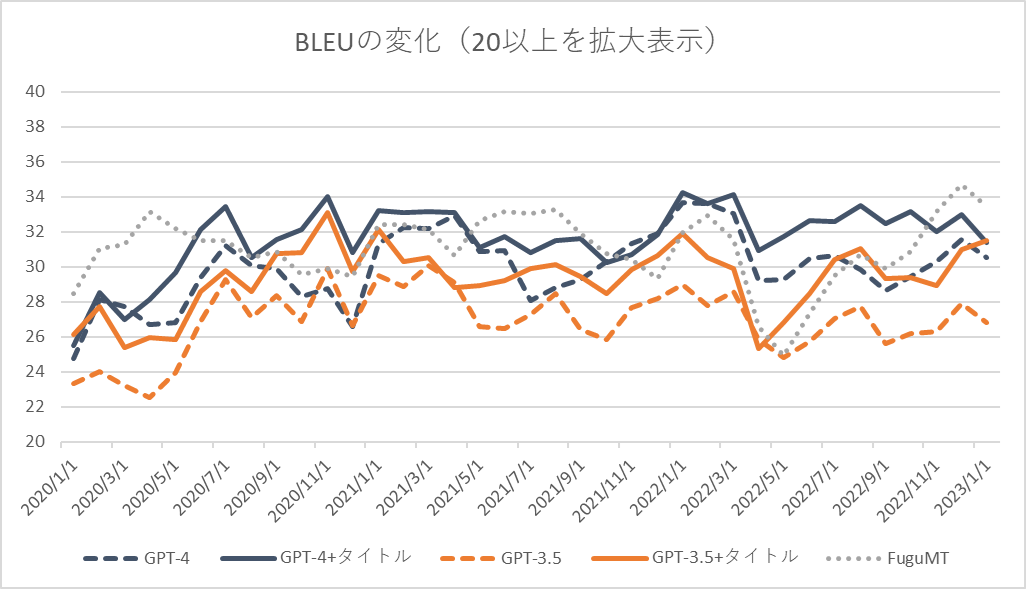
[1] といってもデータ数は微妙で評価指標はBLEU。。。sacrebleu.corpus_bleu( sys, [ref], tokenize=’ja-mecab’)を使用。 [2] GPT-4 (openai.com)によると「GPT-4 generally lacks knowledge of events that have occurred after the vast majority of its data cuts off (September 2021)」とのこと。データ数も少ないので何とも言えないというところではあるが、特に「Webページの内容を記憶しているだけ」な場合はタイトルをプロンプトに入れることで2021/9を境に大幅な性能変化があるかと期待していたが、そのような結果とはなっていない。 [3] 過負荷のためかOpenAI APIのエラー(’openai.error.RateLimitError’)が多発、検証に用いたデータは少なめである。負荷が落ち着いたら全データを使って検証したいと思っている。 [4] 本当はURLを与えるなどより学習データを濃く反映できそうなパターンも実施したかったが時間の関係上断念した [5] 2017年1月~現在までで2700件程度のデータが取得可能、本件に使ったもの以外を含め1/3くらいは目検証済みで残りを検証した後に公開する予定である。翻訳の品質が高く、オープンなライセンスで、検証しやすい長さのドキュメント単位、発表日が明確に記載されている貴重なデータである。機械翻訳モデルの時系列での性能劣化を測るために有用だと思っている。 [6] 自分で目検した。結構大変だが何とかなる量ではある。 [7] FuguMTと僅差だと商用の翻訳サービスの性能よりは低めな気がする。ただ、プロンプトで改善できる、訳のスタイル変更が可能、間違いを指摘してくれるなど単純な性能以外の利点は多くあり、それがチャット形式で可能なのは大きな利点。 [8] 実はFuguMTのクローリングデータはちょうどこの時期に追加したのが最後になっている(OCR用翻訳モデルとVR対応論文翻訳 | ぷるーふおぶこんせぷと (staka.jp))。翻訳が難しいデータなのか、たまたまGPTのデータ期間とFuguMTのデータ期間が近いのか、結論を出すのがとても難しい。Google翻訳やDeepLなどの他のエンジンで試すか、FuguMTの過去バージョンで検証する必要がありそうに思っている。 [9] データはあるが、APIの動作が重く検証できる気がしない…参考までに本検証にかかったコストは15USD程度であった。
GPT-4は全体的に正確かつ流暢に訳せており、前回結果(GPT-3.5、ChatGPT、FuguMT)より優れているように見える。特に3つ目で「デジタル庁」を正しく訳せているのはすごい。「Government as a service」「Government as a startup」「Human-friendly digitalization: No one left behind」の翻訳も良い感じである。
At the outset, Minister Hayashi expressed his respect for Foreign Minister Jaishankar’s leadership in chairing the G20 Foreign Ministers’ Meeting and the Japan-Australia-India-US Foreign Ministers’ Meeting. He stated that as the international community faces a series of major crises, Japan is looking ahead to the G7 Hiroshima Summit in May and the G20 New Delhi Summit in September, and expressed that Japan will continue to work closely with India, which holds the G20 Presidency. In response, Foreign Minister Jaishankar welcomed Minister Hayashi’s visit to India and stated that as G20 Presidency, India would like to cooperate with Japan, which holds the G7 Presidency.
The FSA proposed the draft amendments to the “Guidelines for Administrative Processes” regarding funds transfer service providers for public consultation.The proposal is mainly aimed at providing amendments to the said Guidelines by setting forth supervisory measures to be taken for funds transfer service providers, in response to the “Ministerial Order to Amend the Regulation for Enforcement of the Labor Standards Act to Allow Wage Payment to the Accounts of Funds Transfer Service Providers Designated by the Minister of Health, Labor and Welfare” (provisional English title) [promulgated on November 28, 2022].
The Digital Agency makes best effort to eliminate inefficient technology of the government and focuses on the digitalization of improving systems to support daily lives of people. By guaranteeing the security of data and systems, we aim to accelerate digitalization in a user-driven manner. We commit to “Human-friendly digitalization: No one left behind”, underpinned by the vision of “Government as a service” and “Government as a startup.”
デジタルエージェンシーは、政府の非効率な技術を排除するために最善を尽くし、人々の日常生活を支えるシステム改善のデジタル化に重点を置いています。データとシステムのセキュリティを保証することで、ユーザー主導のデジタル化を加速することを目指しています。私たちは、「Government as a service」と「Government as a startup」のビジョンに裏付けられた「Human-friendly digitalization: No one left back」にコミットします。
LLM (Large Language Model / 大規模言語モデル)の良さはzero / few shotで動くモデルが作れることにあり、No Data, No Codeで特化型モデルであるFuguMTと遜色ない性能を出しているのは正直凄い。[6]によるとGLUEにおけるChatGPTの性能は(得意不得意の差が大きいが平均的には)BERT-baseでfine tuningした結果と同等、BERT-largeやRoBERTaには及ばないとのこと。FuguMTはTransformer世代で約60Mパラメータ(BERT-baseは約110Mパラメータ)であることを考えるとだいたい想定通りの結果ともいえる。
上記結果を「あらゆるユーザが自分の欲しい”AI”をNo Code, No Dataで生み出せ、その性能はBERT-baseを用いてそこそこのデータでfine tuningした結果と同等」と捉えると世の中にかなりのインパクトがあってもおかしくない。Twitterを見ていると様々なタスクにChatGPTを使うユーザがいて、そのタスクには今まで想定されていなかったものが含まれている。データがいらないという点も重要でまさに「AIの民主化」と言えそう。今まで研究者やエンジニアが想像もしなかった用途で有用な”AI”が出てくる可能性は高い。とっても楽しみ。
少し未来のことを考えると今後もLLMの進化は止まらなさそう。上で挙げたfew-shot以上の事例をPromptに埋め込むSoft PromptやCoT(Chain of Thought)[9][10]、PAL(Program-Aided Language models)[11]のようにPromptを工夫する方向性の他、LLM自体の高度化としてマルチモーダル化や外部知識の利用、APIの活用など様々な方向性[12]が研究されている。