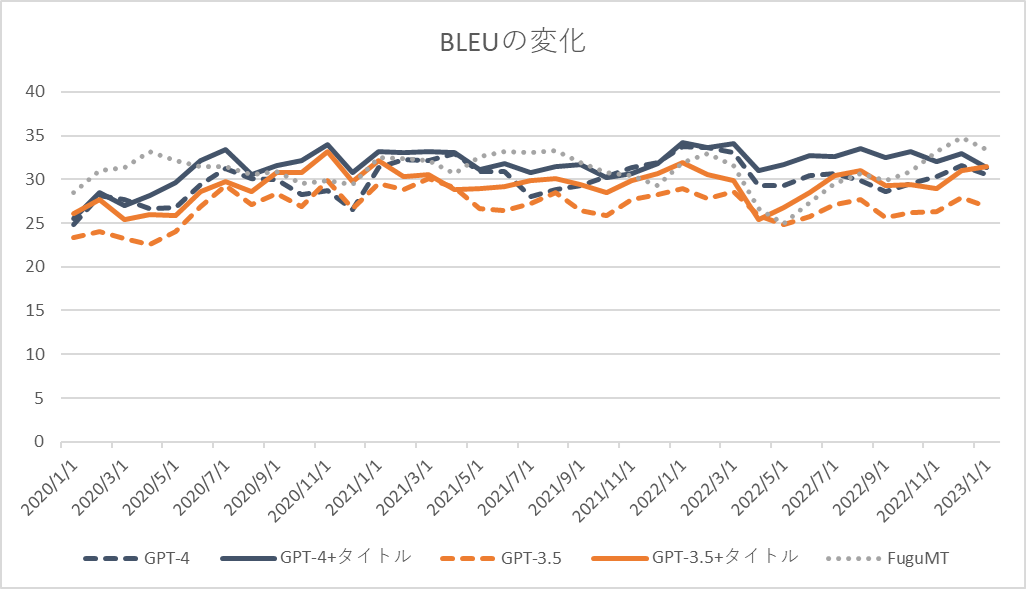
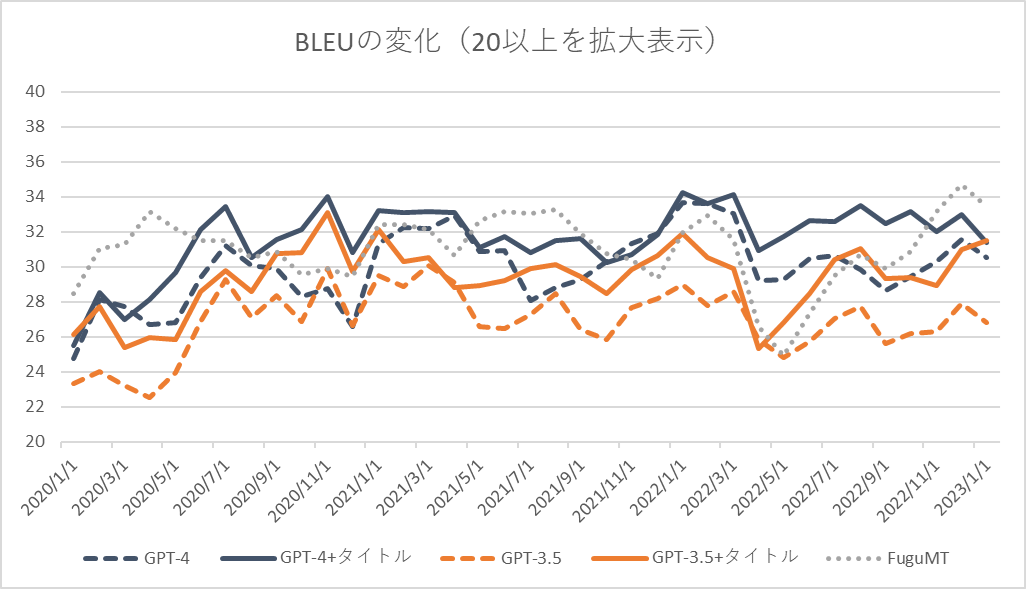
[1] といってもデータ数は微妙で評価指標はBLEU。。。sacrebleu.corpus_bleu( sys, [ref], tokenize=’ja-mecab’)を使用。 [2] GPT-4 (openai.com)によると「GPT-4 generally lacks knowledge of events that have occurred after the vast majority of its data cuts off (September 2021)」とのこと。データ数も少ないので何とも言えないというところではあるが、特に「Webページの内容を記憶しているだけ」な場合はタイトルをプロンプトに入れることで2021/9を境に大幅な性能変化があるかと期待していたが、そのような結果とはなっていない。 [3] 過負荷のためかOpenAI APIのエラー(’openai.error.RateLimitError’)が多発、検証に用いたデータは少なめである。負荷が落ち着いたら全データを使って検証したいと思っている。 [4] 本当はURLを与えるなどより学習データを濃く反映できそうなパターンも実施したかったが時間の関係上断念した [5] 2017年1月~現在までで2700件程度のデータが取得可能、本件に使ったもの以外を含め1/3くらいは目検証済みで残りを検証した後に公開する予定である。翻訳の品質が高く、オープンなライセンスで、検証しやすい長さのドキュメント単位、発表日が明確に記載されている貴重なデータである。機械翻訳モデルの時系列での性能劣化を測るために有用だと思っている。 [6] 自分で目検した。結構大変だが何とかなる量ではある。 [7] FuguMTと僅差だと商用の翻訳サービスの性能よりは低めな気がする。ただ、プロンプトで改善できる、訳のスタイル変更が可能、間違いを指摘してくれるなど単純な性能以外の利点は多くあり、それがチャット形式で可能なのは大きな利点。 [8] 実はFuguMTのクローリングデータはちょうどこの時期に追加したのが最後になっている(OCR用翻訳モデルとVR対応論文翻訳 | ぷるーふおぶこんせぷと (staka.jp))。翻訳が難しいデータなのか、たまたまGPTのデータ期間とFuguMTのデータ期間が近いのか、結論を出すのがとても難しい。Google翻訳やDeepLなどの他のエンジンで試すか、FuguMTの過去バージョンで検証する必要がありそうに思っている。 [9] データはあるが、APIの動作が重く検証できる気がしない…参考までに本検証にかかったコストは15USD程度であった。
GPT-4は全体的に正確かつ流暢に訳せており、前回結果(GPT-3.5、ChatGPT、FuguMT)より優れているように見える。特に3つ目で「デジタル庁」を正しく訳せているのはすごい。「Government as a service」「Government as a startup」「Human-friendly digitalization: No one left behind」の翻訳も良い感じである。