GPT-4の翻訳性能を外務省WEBサイトのテキスト(日本語/英語)を用いて定量的[1]に測ってみた。
検証結果からGPT-4の翻訳性能はGPT-3.5より優れていると言えそう(FuguMTより若干上)。期間別の比較(後述)も行っているが発表されているGPT-4の学習データ期間前後では大きな性能変化はなかった。一方で詳細検討が必要な気がしている[2]。
| モデル | 概要 | BLEU |
| GPT-4 | gpt-4-0314を利用(ゼロショット) | 30.19 |
| GPT-4 + タイトル | gpt-4-0314を利用し対応するページのタイトル(英語・日本語の両方)を与えたもの | 31.82 |
| GPT-3.5 | gpt-3.5-turbo-0301を利用(ゼロショット) | 27.16 |
| GPT-3.5 + タイトル | gpt-3.5-turbo-0301を利用し対応するページのタイトル(英語・日本語の両方)を与えたもの | 29.58 |
| FuguMT | 英語文書をGitHub – nipunsadvilkar/pySBDにより行に分割し、FuguMTで翻訳 | 31.30 |
性能評価の方法
性能評価は下記の条件で実施した。
- ChatGPT API(gpt-3.5-turbo-0301)、GPT-4 API(gpt-4-0314)、FuguMT(staka/fugumt-en-ja · Hugging Face)を比較。英語文を日本語文に翻訳し、その性能を評価した。
- 評価指標はBLEUで、使用したツールやtokenizerは前回と同じ(sacrebleu –tokenize ja-mecab)である
- データセットは外務省WEBサイトのプレスリリースのうち日本語、英語が対応しているページを利用した。詳細はデータセットの作成に記載する。
- 期間は2020年1月~2023年3月、月ごとに5件のプレスリリースを選択[3]、全195件
- 既存のデータセットはGPT-4、GPT-3.5の学習データとして使われている可能性があり利用を避けた。(加えて性能評価のために適した品質と言えないものも少なくない。)
- プロンプトは前回のもの(機械翻訳でのChatGPT vs GPT-3.5 vs FuguMT | ぷるーふおぶこんせぷと (staka.jp))を使用、プレスリリースのタイトル(日・英)の対応を参照用として与えたパターンも比較対象とした
- タイトルを与えることで、参考訳として使用する事及び訳のスタイルを官公庁っぽくすることを狙っている [4]
- 学習データに外務省のサイトが入っている場合(おそらく入っていると思うが)そのデータを色濃く反映する効果も狙っている
- 性能評価は全体、2021年9月[2]前後での検証、月別(ある月以降3ヶ月間分のプレスリリースを使用)で評価した。月別の評価と言いつつ3ヶ月移動平均のような処理になっている。(データが少ないことによる苦肉の策)
データセットの作成
データセットは外務省ホームページのPress Releases | Ministry of Foreign Affairs of Japan (mofa.go.jp)を用いて下記手順で作成した。使用したデータは整理後に公開予定[5]。
- プレスリリースのうち、日本語と英語の対応が取れるものを取得
- 日本語のページと英語のページから本文とタイトルを抽出
- 英語のページから日付を抽出
- 日本語のページと英語のページを目で比較し、どちらか一方のみにある部分を削除
- 日本語だけに補足や経緯がある、参考リンクが日本語と英語のページで異なるなど微妙な差異があるため、その部分は対応が必要である。[6]
- 2020年1月~2023年3月の記事について長さがちょうどよいものを5件/月を選択した
- 月内の全記事の中から一定期間ごとになるように5件選択
- 300文字~1600文字の記事を選択
検証結果
検証結果は下表・下図の通り。
| モデル | 期間 | BLEU |
| GPT-4 | 全期間 | 30.19 |
| GPT-4 | 2021/09/01以前 | 29.66 |
| GPT-4 | 2021/10/01以降 | 30.82 |
| GPT-4 + タイトル | 全期間 | 31.82 |
| GPT-4 + タイトル | 2021/09/01以前 | 31.30 |
| GPT-4 + タイトル | 2021/10/01以降 | 32.15 |
| GPT-3.5 | 全期間 | 27.16 |
| GPT-3.5 | 2021/09/01以前 | 27.04 |
| GPT-3.5 | 2021/10/01以降 | 26.87 |
| GPT-3.5 + タイトル | 全期間 | 29.58 |
| GPT-3.5 + タイトル | 2021/09/01以前 | 29.34 |
| GPT-3.5 + タイトル | 2021/10/01以降 | 29.59 |
| FuguMT | 全期間 | 31.30 |
| FuguMT | 2021/09/01以前 | 31.65 |
| FuguMT | 2021/10/01以降 | 30.70 |
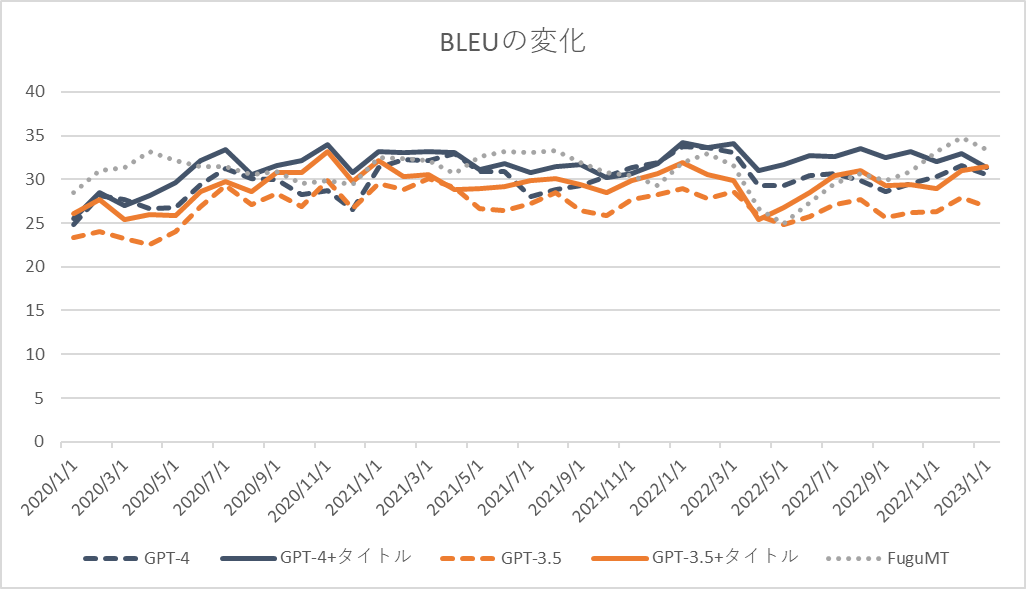
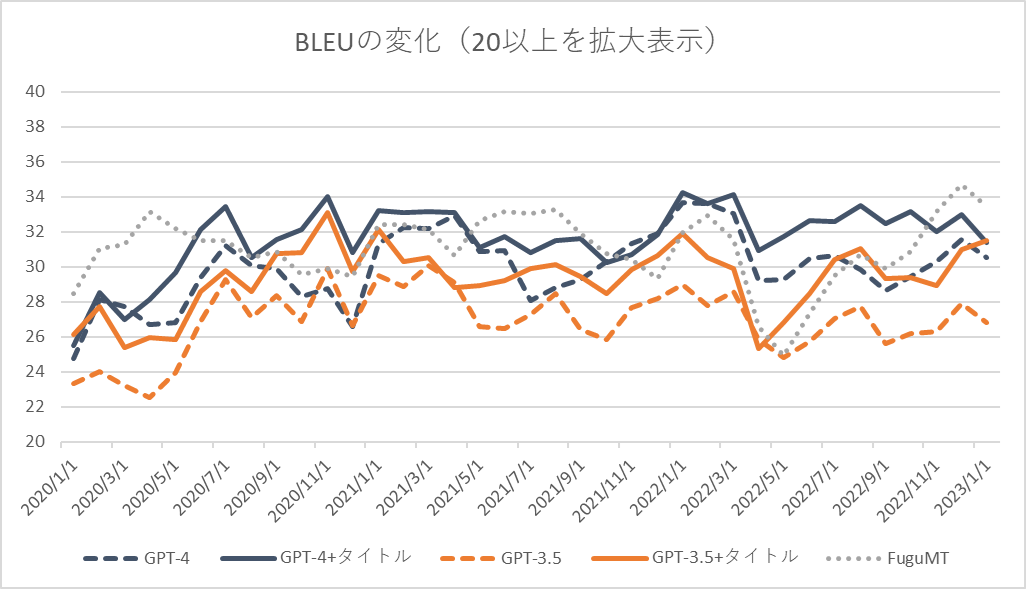
まとめ
GPT-4の翻訳性能を外務省WEBサイトの日本語-英語対応を使って検証した。結果としてGPT-4は翻訳性能においてGPT-3.5よりも大幅に優れていた。タイトルを参考訳として使用可能な状況ではFuguMTのような翻訳特化モデルを超える性能を発揮している[7]。
GPT-4の学習データ期間は2021年9月までとのことだが、翻訳性能の変化からはその時期を境にした性能変化は見られなかった。2022年3月~4月ごろに性能の変化がみられるが、FuguMTでも同傾向であり単純に訳が難しいデータになっているだけの可能性がある[8]。
BLEUの経年変化はタイトル行を入れてもFuguMTと概ね同じである。(おそらく学習データに含まれているであろう)ページの日本語訳のコピーを出している場合はFuguMTと動きが異なるはずで、そのような不適切な動作はしていないものと思われる。BLEUの変化のブレが激しくデータを増やす、比較するモデルを変えるなどしての再検証が必要と思われる[9]。
現在のGPT-4 APIでは画像入力ができないが、できるようになったらそれを含めて検証を行いたい。官公庁のサイトでは画像付きの記事も多く、画像+機械翻訳の性能検証は可能だと考えている。
脚注
[1] といってもデータ数は微妙で評価指標はBLEU。。。sacrebleu.corpus_bleu( sys, [ref], tokenize=’ja-mecab’)を使用。
[2] GPT-4 (openai.com)によると「GPT-4 generally lacks knowledge of events that have occurred after the vast majority of its data cuts off (September 2021)」とのこと。データ数も少ないので何とも言えないというところではあるが、特に「Webページの内容を記憶しているだけ」な場合はタイトルをプロンプトに入れることで2021/9を境に大幅な性能変化があるかと期待していたが、そのような結果とはなっていない。
[3] 過負荷のためかOpenAI APIのエラー(’openai.error.RateLimitError’)が多発、検証に用いたデータは少なめである。負荷が落ち着いたら全データを使って検証したいと思っている。
[4] 本当はURLを与えるなどより学習データを濃く反映できそうなパターンも実施したかったが時間の関係上断念した
[5] 2017年1月~現在までで2700件程度のデータが取得可能、本件に使ったもの以外を含め1/3くらいは目検証済みで残りを検証した後に公開する予定である。翻訳の品質が高く、オープンなライセンスで、検証しやすい長さのドキュメント単位、発表日が明確に記載されている貴重なデータである。機械翻訳モデルの時系列での性能劣化を測るために有用だと思っている。
[6] 自分で目検した。結構大変だが何とかなる量ではある。
[7] FuguMTと僅差だと商用の翻訳サービスの性能よりは低めな気がする。ただ、プロンプトで改善できる、訳のスタイル変更が可能、間違いを指摘してくれるなど単純な性能以外の利点は多くあり、それがチャット形式で可能なのは大きな利点。
[8] 実はFuguMTのクローリングデータはちょうどこの時期に追加したのが最後になっている(OCR用翻訳モデルとVR対応論文翻訳 | ぷるーふおぶこんせぷと (staka.jp))。翻訳が難しいデータなのか、たまたまGPTのデータ期間とFuguMTのデータ期間が近いのか、結論を出すのがとても難しい。Google翻訳やDeepLなどの他のエンジンで試すか、FuguMTの過去バージョンで検証する必要がありそうに思っている。
[9] データはあるが、APIの動作が重く検証できる気がしない…参考までに本検証にかかったコストは15USD程度であった。
その他
色々なところで指摘されている事でもあるが、試行しているとGPT-3.5までと比べてGPT-4は日本語性能が大きく向上している。機械翻訳でのBLEUの向上はそれを裏付けている。GPT-3.5までであれば特化型モデル > GPT(LLM+prompt)だったがGPT-4ではそうでもなさそう。おそらく数か月すれば検証結果がそろうはずで興味津々。
本件の検証の目的の一つは2021年9月を境に性能が劣化するか?だったが残念ながら裏付けが取れなかった…全データを使っているわけではなく変化点っぽいものも見えなくはないのでより詳細な検討を行いたいところ。メンバシップ攻撃のようなことをやっている人達もいるかもだが、個人的にはデータの期間をはっきりさせるというよりはleakっぽい理由で性能が高く見えるのかそうでないのか?をはっきりさせたいと思っている。Home | RealTime QAのような取り組みも参考になりそう。
日本語性能の向上やプロンプトの探索などを見るに結構な社会的インパクトを与えるのは間違いなく、どう使っていくか?を考えていく必要がある。初期のインターネットと同じワクワク感がありとても楽しいと思う一方でディスラプトの怖さもある。OpenAIは結構な影響を予測しているFugu-MT 論文翻訳(概要): GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models (fugumt.com)が、実際どうなるかはここ数ヶ月で決まるんだろうなーと思う。
社会的なインパクトにも興味があるが、LLMの内部動作の理解、特にマルチリンガルな能力の獲得やIn-Context Learningが可能な理由にも興味がある。マルチモーダルさが入った時の動きも知りたいところ。この手の検証はAPIだととてもやりにくいのでオープンなChatGPT likeモデルに期待大。色々理由はあるのだろうが詳細が非公開というのはやはり辛い。